
近年来,大语言模型(Large Language Models, LLMs)的训练主要依赖两种方式:一是通过大量人工标注数据进行强化学习人类反馈(RLHF),如ChatGPT,但成本高昂且可能引入偏见;二是依赖可验证标准答案的强化学习验证结果(RLVR),如DeepSeek的RLVR,适用于数学、编程等领域,但难以推广到开放域任务。随着AI能力逐渐接近甚至超越人类,一个关键问题浮现:能否让模型仅凭自身产生的内在信号,摆脱对外部监督的依赖?UC Berkeley团队针对这一问题提出了突破性框架——RLIF(Reinforcement Learning from Internal Feedback,内省反馈强化学习),并开发了具体实现方法Intuitor,通过优化模型自身信心实现复杂推理,复刻并超越了DeepSeek-R1的长思维链推理能力。这一成果迅速成为AI研究领域的热门话题。
RLIF与Intuitor:内省反馈的革新
RLIF是一种新型强化学习框架,允许大模型通过内部信号学习,无需外部奖励或标注数据。其核心理念是利用模型自身的“自信程度”(self-certainty)驱动学习过程。Intuitor作为RLIF的具体实现,提出了一种创新的训练方法,通过计算模型预测分布与均匀分布之间的**KL散度(Kullback-Leibler Divergence)**来量化自信程度,并将其作为强化学习中的奖励信号。
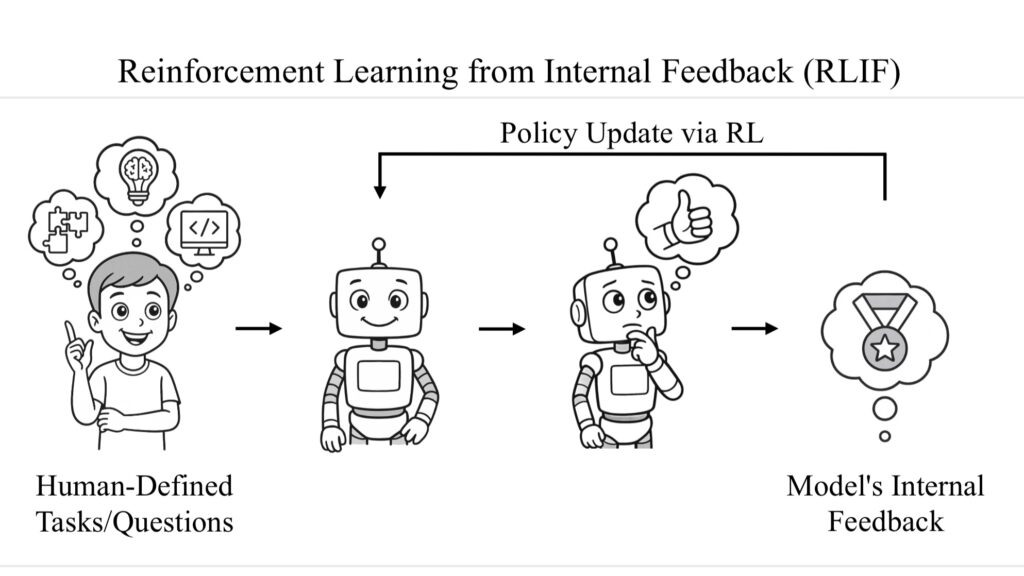

Intuitor的工作原理
Intuitor通过以下步骤实现内省反馈:
- 量化自信程度:使用KL散度衡量模型预测分布与完全不确定状态(均匀分布)的差异。较高的KL散度表明模型对某个答案更有信心,较低的KL散度则表示犹豫或不确定。
- 优化目标:通过强化学习优化模型,使其在推理过程中逐步提高对正确答案的信心,同时降低对错误答案的信心。这一过程不依赖外部真实答案,而是通过模型自身的内省信号驱动。
- 长思维链推理:Intuitor特别适用于长思维链(Chain-of-Thought, CoT)推理任务,通过优化推理链每一步的自信程度,确保整体推理的可靠性和准确性。
UC Berkeley团队共同一作Xuandong Zhao将这一成果概括为:“大模型无需接触真实答案,仅通过优化自己的信心,就能学会复杂推理。”这一方法不仅降低了训练成本,还为AI在数据稀缺或主观性强的领域(如自然语言推理、创意写作、伦理决策)提供了新的可能性。
RLIF与Intuitor的技术细节(简略)
1. RLIF框架概述
RLIF是一种强化学习框架,旨在让大语言模型(LLMs)通过内部信号(而非外部奖励或标注数据)进行学习。其核心思想是利用模型自身的预测分布特性(如自信程度)作为奖励信号,驱动复杂推理任务的学习。Intuitor是RLIF的具体实现,专注于优化长思维链(Chain-of-Thought, CoT)推理。
关键创新:
- 无外部监督:无需真实答案或人类反馈,依赖模型内省信号。
- 自信程度优化:通过KL散度量化模型的预测确定性,作为强化学习奖励。
- 适用于长思维链:通过逐阶段优化推理步骤,提升多步推理的可靠性。
2. Intuitor的数学与算法机制
自信程度的量化:KL散度
Intuitor使用KL散度(Kullback-Leibler Divergence)来衡量模型预测分布与均匀分布之间的差异,作为自信程度的度量。数学上,KL散度定义为:

直观解释:
- 当模型对某个输出高度确定(预测分布集中于少量选项),KL散度较高,表示高自信。
- 当模型不确定(预测分布接近均匀),KL散度较低,表示低自信。
Intuitor将KL散度作为奖励信号,鼓励模型在推理过程中产生高自信的预测,同时确保这些预测在推理链中逐步趋向正确答案。
Intuitor采用强化学习(RL)优化模型,具体使用Proximal Policy Optimization (PPO) 算法。PPO是一种广泛使用的RL算法,通过平衡探索与利用来优化策略。Intuitor的优化目标是最大化期望奖励,其中奖励由KL散度定义。
实验成果:从数学到跨领域泛化
UC Berkeley团队在多种复杂推理任务上验证了Intuitor的有效性,实验结果令人瞩目:
- 数学基准测试:在GSM8K和MATH500等数学问题集上,Intuitor的性能与传统方法(如Group Relative Policy Optimization, GRPO)相当,证明其在有明确答案的领域也能达到高水平。
- 代码生成任务:在LiveCodeBench v6和CRUXEval等基准上,Intuitor展现出更强的泛化能力,甚至优于传统方法。这表明Intuitor能够在无需金标准答案或测试案例的情况下,适应新的任务领域。
- 开放域任务:Intuitor在生成连贯的故事、回答伦理困境问题等主观性任务中表现出色,展示了其在通用智能场景中的潜力。
这些成果表明,内在模型信号(如自信程度)可以有效驱动跨领域学习,为自主AI系统的开发提供了可扩展的替代方案。Intuitor的成功复刻并超越了DeepSeek-R1的长思维链推理能力,标志着大模型训练范式的重大转变。
与传统方法的对比
传统大模型训练方法的局限性显而易见:
- RLHF(强化学习人类反馈):依赖人工标注,成本高昂且可能引入主观偏见。高质量标注数据的获取在开放域任务中尤其困难。
- RLVR(强化学习验证结果):依赖明确的对错答案,局限于数学、编程等可验证领域,无法处理主观性强或答案不唯一的任务。
相比之下,Intuitor通过内省反馈摆脱了对外部监督的依赖,具有以下优势:
- 成本低:无需人工标注或标准答案,显著降低训练成本。
- 通用性强:适用于开放域任务,突破了传统方法的领域限制。
- 模拟人类直觉:通过优化自信程度,Intuitor模仿了人类在面对复杂问题时依靠直觉和自我评估的过程,为构建更接近人类智能的AI提供了新思路。
社区反响与学术影响
RLIF和Intuitor的提出引发了AI研究社区的广泛关注。相关研究成果发表在论文《Learning to Reason without External Rewards》(arXiv:2505.19590)中,作者包括Xuandong Zhao、Zhewei Kang、Aosong Feng、Sergey Levine和Dawn Song,均来自UC Berkeley。论文提交日期为2025年5月26日,代码已开源(GitHub: Intuitor)。
“UC Berkeley发布了一项突破性研究,LLMs可以通过信任自己的自信分数进行学习,而无需任何地面真实标签或奖励信号。只需内部反馈(RLIF)即可。它们使用‘自自信’来指导学习——如果模型感觉确定,它就算是赢了。这太疯狂了。”这一讨论反映了社区对RLIF潜力的期待。
挑战与未来展望
尽管RLIF和Intuitor展示了巨大潜力,但仍面临一些挑战:
- 稳定性与过自信风险:过度优化自信程度可能导致模型对错误答案表现出过高的信心,影响推理可靠性。如何平衡自信与准确性是未来研究的关键。
- 计算成本:计算KL散度和进行强化学习优化需要较高计算资源,尤其在大规模模型上。降低计算开销以推广应用是重要课题。
- 伦理与安全性:在缺乏外部监督的情况下,模型可能在敏感任务(如伦理决策)中产生不可预测结果,确保安全性和可控性至关重要。
未来,RLIF和Intuitor可能与外部奖励方法(如RLHF或RLVR)结合,进一步提升性能。研究团队计划探索如何让模型在新型领域实现自主技能获取,并推动可扩展的自我改进系统。潜在应用包括:
- 教育:自动生成教学反馈,辅助学生学习。
- 医疗:提供基于复杂推理的诊断建议。
- 法律:分析复杂案例,支持决策过程。
结论
RLIF和Intuitor代表了大模型强化学习的新范式,通过内省反馈实现了复杂推理的可能性。这一方法不仅降低了训练成本,还为AI在开放域任务中的应用开辟了新前景。UC Berkeley团队的研究为构建自主、通用智能系统奠定了基础,标志着AI训练从依赖外部监督向自主学习的重大转变。随着研究的深入,内省反馈机制有望成为下一代智能系统的核心技术。