
小米于2025年4月30日发布了其首个开源推理大模型Xiaomi MiMo,其中MiMo-7B-RL模型因其卓越的表现而备受关注。该模型仅有7B参数,但在数学推理(AIME 24-25)和代码竞赛(LiveCodeBench v5)等公开测评中,超过了OpenAI的闭源模型o1-mini和阿里巴巴的开源模型QwQ-32B-Preview(参数量为32B)。


同时,预训练和后训练阶段中数据和算法等多层面的创新联动驱动,推动MiMo推理能力提升。其预训练的核心是让模型见过更多推理模式,后训练的核心是高效稳定的强化学习算法和框架。
目前,MiMo-7B已开源4个模型至HuggingFace。
小米介绍,MiMo是公司新成立的“小米大模型Core团队”的初步尝试,并称“2025年虽看似是大模型逐梦的后半程,但我们坚信AGI的征途仍漫长。”
去年4月,小米宣布组建AI实验室大模型团队,AI领域相关研发人员超1200人。去年12月,有消息称小米正在着手搭建自己的GPU万卡集群,将对AI大模型大力投入。
MiMo-7B-RL在多个推理相关任务上表现出色,具体表现如下:
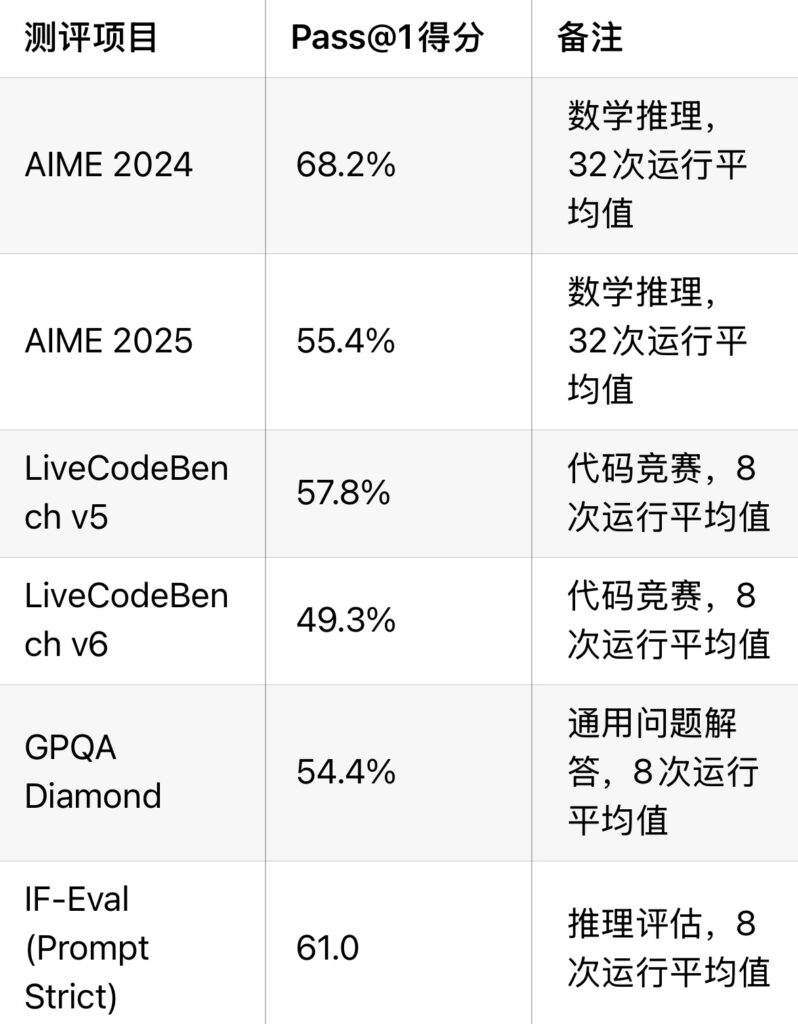
这些成绩表明,MiMo-7B-RL在数学和代码推理任务上表现优异,尤其是在AIME和LiveCodeBench测评中超过了参数量更大的竞争对手。需要注意的是,这些基准测试主要聚焦于推理能力,其结果可能不代表模型在其他通用任务(如自然语言生成或多模态处理)上的表现。
MiMo-7B-RL的成功很大程度上归功于小米的创新训练策略。以下是关键细节:
• 预训练阶段:
• 使用了约25万亿个令牌进行预训练,其中包括2000亿个专门为推理设计的令牌。
• 采用了三阶段数据混合策略,并优化了数据预处理管道,包括多维度数据过滤和生成多样化合成推理数据。
• 引入了多令牌预测(MTP)作为额外的训练目标,声称这可以在不牺牲输出质量的情况下缩短推理时间。MTP层在预训练和监督微调(SFT)阶段进行调整,在强化学习(RL)阶段冻结,接受率约为90%,用于推测性解码。
• 强化学习阶段:
• 使用了13万个数学和代码问题进行后训练,设计了基于规则的准确性奖励和测试难度驱动的代码奖励机制。
• 引入了“简单数据再采样”策略,以稳定训练过程,特别是在处理复杂算法时解决稀疏奖励信号的问题。
• 基础设施优化:
• 小米开发了“无缝回放引擎”(Seamless Rollout Engine),显著减少了GPU停机时间,使训练速度提高了2.29倍,验证速度提高了1.96倍。
• 该引擎还支持MTP在vLLM框架中的应用,进一步增强了RL系统的推理稳定性。
这些创新表明,模型性能的提升不仅依赖于参数量,还与训练数据质量、奖励机制设计和基础设施效率密切相关。